Introduction
Welcome to Week 2 of the 2024 CRMA Workout Wednesday challenge. This week we will be working with Text Clustering in Einstein Discovery Models. Text Clustering, sometimes called Mining or Data Mining, is the function of analyzing unstructured data to group similar context or pieces of text into categories or… clusters.
Often times our models are ingesting tabular data to analyze and predict but how can we derive value from data that is not collected in this standard? Unstructured Data can be collected in the form of: Customer Feedback, Product Reviews, Survey Responses, Chat Dialogue, Emails, etc.
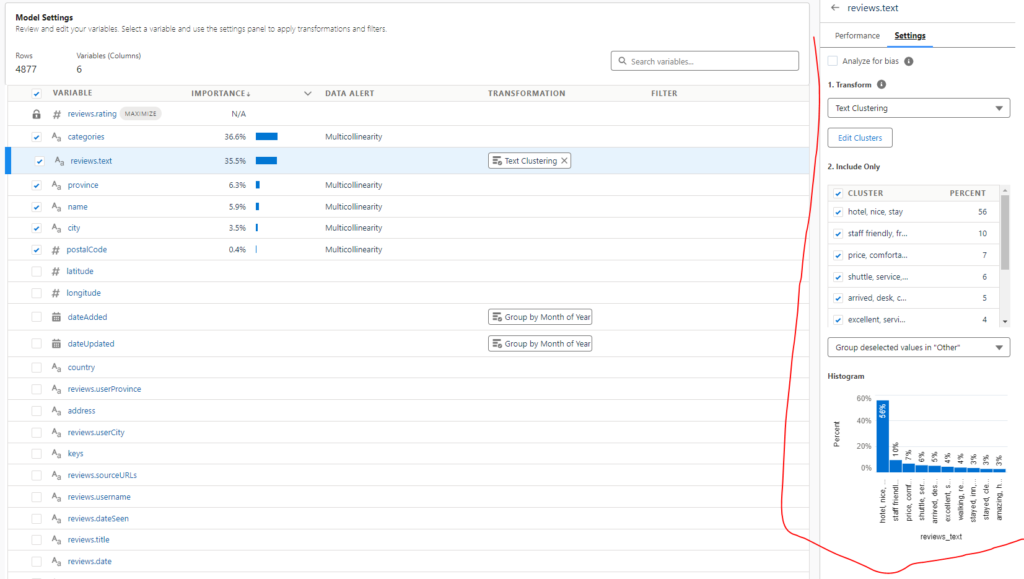
In this challenge you will create an Einstein Model to analyze review ratings and review comments. By utilizing the text clustering feature in the model, you can determine what key words within the review text have an impact on the user review rating.
Requirements
- Create a model to analyze review rating
- Include City, Province, Name, Review Text and Categories in your settings
- Train your model and review the data insights
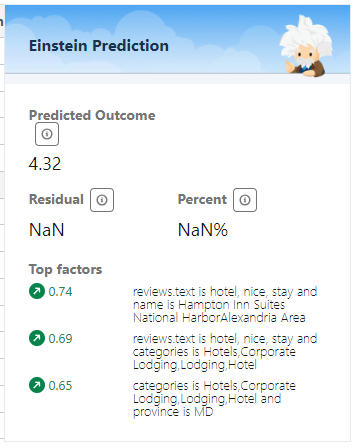
- Can you determine which key words in Review Text have a positive/negative impact on Rating?
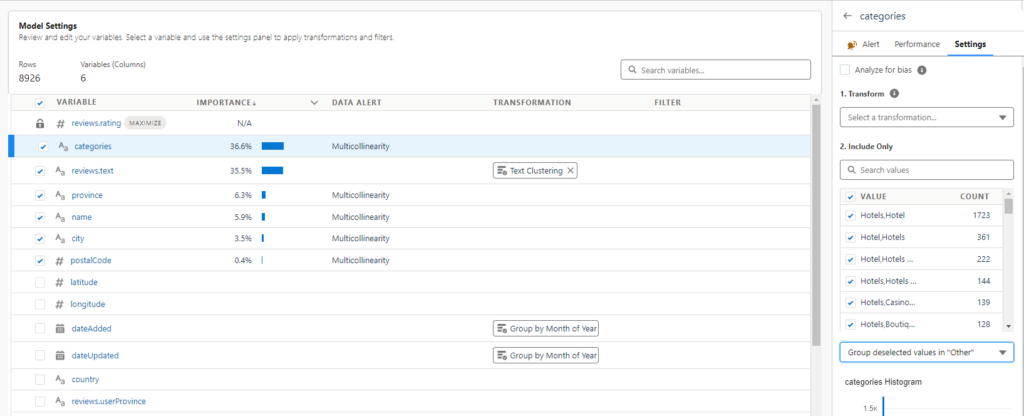
- What change can you implement in the Categories setting to group a large amount of undefined values? Hint: it shows in the screen shot below
- Update your model to Detect Sentiment in the Review Text setting and re-run.
- What categories had the most positive impact on reviews?
- you can’t create a model without a dataset
- you have to manually configure the unstructured data settings before running your model